Page History
| Excerpt |
|---|
| PS1 data processing includes many steps to go from raw image data to the archived data products. The raw images are detrended to remove instrument signatures, and then deprojected into images in a regular grid of projection cells. These |
| "warps |
| " are then combined into "stacks." Various forms of |
| point-source and extended-object photometry are performed on the warps and stacks. |
INSERT FLOWCHART HERE
The following information is taken from Magnier et al. and Waters et al., which should be cited appropriately. The starting point for the PS1 data archive is at Pan-STARRS1 data archive home page.
PS1 uses the 1.4 giga-pixel GPC1 Camera camera (see PS1 GPC1 camera) to image the sky north of declination −30 degree declination. The GPC1 Camera is composed of degrees. The camera detector system has 60 orthogonal transfer array arrays (OTA) devices, each of which is has an 8 × 8 grid of readout cells with (X x X (each with 590×598 pixels). These images are reduced with the PS1 IPP pipeline. The Processing Version 3 (PV3) reduction, which all the publicly available data in this archive is based on, represents the third full reduction of the PS1 data set. The first two reductions were used internally for pipeline optimization and the development of the initial photometric and astrometric reference catalog, and are not publicly available.
For the PV3 processing, large contiguous regions were defined, and the images for all exposures within that region launched for the processing (see paper by Waters et al. for more details). The processing is divided into individual stages. The first step is the CHIP stage processing, which performs the Image Detrending PS1 Exposure detrending (e.g., bias subtraction, dark current correction, flat fielding, defringing, masking), as well as a single epoch photomety. Following the CHIP stage is the CAMERA stage, in which the astrometry and photometry for the entire exposure is calibrated by matching the detections against the reference catalog. This stage also performs masking updates based on the now-known positions and brightnesses of stars that create dynamic feature.
The WARP stage is the next to operate on the data, transforming the detector oriented chip stage images onto common sky oriented PS1 Warp Imagesimages that have fixed sky projections. Point-source and extended source photometry is performed on these warps. When all WARP stage processing is done for the region of the sky, STACK processing is performed to construct deeper, fully populated PS1 Stack Imagesimages from the set of warp images that cover that region of the sky. Point source Source detection and photometry is done on both the warp and stack images (see Stack Objects and Photometry)performed on these stacks, which are then combined into objects (see PS1 Stack objects and photometry). Source detection and photometry is explained in more detail in the PS1 Source extraction and catalogs webpage.
Beyond the STACK stage, a series of additional stages are performed. Transient features are identified in the DIFF stage, which takes input warp and/or stack data and performs image differencing. Further photometry is performed in the STATICSKY and SKYCAL stages, which add extended source fitting to the point source photometry of objects detected in the stack images, and calibrate the results against the reference catalog. The FULLFORCE stage takes the catalog output of the skycal stage, and uses the objects detected in that to perform forced photometry on the individual warp images.
-----------------------------------
extra material to be used for level 2 pages:
Key points
- Following data administration (transfer and database management), each exposure is processed chip by chip for each detector. This is to remove instrumental signatures and to detect sources.
- Instrumental signatures are removed by "detrending," described by C. Z. Waters and the IPP Team: "Pan-STARRS Pixel Processing: Detrending, Warping, Stacking," in draft. These steps are described in separate web pages.
- Following detrending, a single chip image is created and then sources are detected and characterized, with resultant data products:
- Detrended chip image
- Variance image
- Mask image
- FITS catalog of detected sources; note that "sources" here refers to a single detection in a single image and that many of these may be spurious.
- The PSF model and background model are also saved, along with summary metadata.
- Sky positions of detected sources are next determined using a model of the camera performance. These are matched to catalogs and the astrometry is iterated.
- The same reference catalog is used for photometric calibration of the images.
- Image masks are created to take account of optical ghosts, glints, saturated stars, diffraction spikes, and electronic crosstalk. These image masks are used to update the earlier mask images.
- JPEG images are created of the entire focal plane for convenient display.
- The images are transformed onto a system of pixel-grid images common across all of Pan-STARRS; these are called skycells. This is to enable later stacking of images and difference image analysis. This process is called "warping."
- Output from the warping stage includes skycell images with signal, variance, and mask information.
- These images will be available in DR2.
- Skycell images from the warp process are co-added to make deeper "stack" images with better signal-to-noise.
- Stacks also fill in gaps in coverage.
- Stacks are created from multiple exposures from a single night and from multiple nights.
- The stacked images have sources detected independently from that done for individual exposures. This is "stack photometry."
- Sources are detected to 5-sigma significance.
- Detected sources are merged into a single master list.
- If a source is detected in at least two bands (or just in the y band), then a PSF model is fitted to the images for the other bands. This is "forced photometry."
- Stack photometry output consists of FITS tables in a single file, one file for each filter. The tables include: measurements of sources based on the PSF model; aperture-like parameters such as the Petrosian flux and radius; the convolved galaxy model fits; radial aperture measurements.
- Stack images have some limitations due to difficulty in modeling PSF variations in time and across the instrument field of view. Some images have significant fractions missing due to the masks, and this leads to significant PSF variations over small distances in the final images.
- This is addressed by using sources detected in stack images and then performing forced photometry on the individual warp images that were used to create the stack.
- Measurements include aperture magnitudes, Kron magnitudes, and moments.
- For the faintest sources, measurements from a single warp image may have low significance but will be satisfactory for the combined measurements.
- Convolved galaxy models are remeasured on the warp images during the forced photometry stage.
- Difference images are created to search for moving objects and transients. This is enhanced by matching the PSFs of the two images.
Detailed descriptions
The following is from E. A. Magnier and the IPP Team: "Pan-STARRS Data Processing Stages," in draft.
Processing Database
A critical element in the Pan-STARRS IPP infrastructure is the processing database. This database, using the mysql database engine, tracks information about each of the pro- cessing stages. It is used as the point of mediation of all IPP operations. Processing stages within the IPP perform queries of the database to identify the data to be processed at a given stage. As the processing for a particular stage is completed, summary information about the stage is written back to the database. In this way, the database records this history of the processing, and also provides the information needed to successive processing stages to begin their own tasks.
The processing database is colloquially referred to as the ‘gpc1’ database, since a single instance of the database is used to track the processing of images and data products related to the PS1 GPC1 camera. This same database engine also has instances for other cameras processed by the IPP, e.g., GPC2, the test cameras TC1, TC3, the Imaging Sky Probe (ISP), etc.
Within the processing database, the various processing stages are represented as a set of tables. In general, there is a top level table which defines the conceptual list of processing items either to be done, in progress, or completed. An associated table lists the details of elements which have been processed. For example, one critical stage is the Chip processing stage, discussed below, in which the individual chips from an exposure are detrended and sources are detected. Within the gpc1 database, there is a top-level table called ‘chipRun’ in which each exposure has a single entry. Associated with this table is the ‘chipProcessedImfile’ table, which contains one row for each of the (up to 60) chips associated with the exposure. The top-level tables, such as chipRun, are populated once the system has decided that a specific item (e.g., an exposure) should be processed at that stage. Initially, the entry is given a state of ‘run’, denoting that the exposure is ready to be processed. The low-level table entries, such as the chipProcessedImfile entries, are only populated once the element (e.g., the chip) has been processed by the analysis system. Once all elements for a given stage, e.g., chips in this case, are completed, then the status of the top-level table entry (chipRun) are switched from ‘run’ to ‘done’.
Download from Summit
As exposures are taken by the PS1 telescope & camera system, the 60 OTA CCDs are read out by the camera software system and each chip is written to disk on computers at the summit in the PS1 facility. The chip images are written to a collection of machines in the PS1 facility called the ‘pixel servers’. After the images are written to disk, a summary listing of the information about the exposure and the chip images are written to an http server system called the ‘datastore’. The datastore exposes, via http, a list of the exposures obtained since the start of the PS1 operations. Requests to this server may restrict to the latest by time. Each row in the listing includes basic information about the exposure: an exposure identifier (e.g., o5432g0123o; see ?? for details), the date and time of the exposure, etc. The row also provides a link to a listing of the chips associated with that exposure. This listing includes a link to the individual chip FITS files as well as an md5 CHECKSUM. Systems which are allowed access may download chip FITS files via http requests to the provided links.
During night-time operations, while the telescope is observing the sky and the camera subsystem is saving images to the pixel servers and adding their information to the datastore list, the IPP subsystem called ‘summitcopy’ monitors the datastore in order to discover new exposures ready for download. Once a new exposure has been listed on the datastore, summitcopy adds an entry of the exposure to a table in the processing database (summitExp). This tells the summitcopy to look for the list of chips, which are then added to another table (summitImfile). The summitcopy system then attempts to download the chips from the summit pixel servers with an http request. As the chip files are downloaded, their md5 checksum values are calculated and compared with the value reported by the camera subsystem / datastore. Download failures are rare and marked as a non-zero fault, allowing for a manual recovery, rather than automatically rejecting the failed chips.
Image Registration
Once chips for an exposure have all been downloaded, the exposure is ready to be registered. In this context, ‘registration’ refers to the process of adding them to the database listing of known, raw exposures (not to be confused with ’registration’ in the sense of pixel re-alignment). The result of the registration analysis is an entry for each exposure in the rawExp table, and one for each chip in the rawImfile table. These tables are critical for downstream processing to identify what exposures are available for processing in any other stage. In the registration stage, a large amount of descriptive metadata for each chip is added to the rawImfile table, some of which is extracted from the chip FITS file headers (e.g., RA, DEC, FILTER) and some of which is determined by a quick analysis of the pixels (e.g., mean pixel values, standard deviation). The chip-level information is merged into a set of exposure-level metadata and added to the rawExp table entry. The exposure-level metadata may be the same as any one of the chip, in a case where the values are duplicated across the chip files (e.g., the name of the telescope or the date & time of the exposure), or it may be a calculation based on the values from each chip (e.g., average of the average pixel values).
Unlike much of the rest of the IPP stage, the raw exposures may only have a single entry in the registration tables of the processing database tables (rawExp and rawImfile).
Chip Processing
The science analysis of an exposure begins with the processing of the individual chips, the Chip Processing stage. This analysis step has two main goals: the removal of the instrumental signature from the pixel values (detrending) and the detection of the sources in the objects. In the Chip stage, the individual chips are processed independently in parallel within the data processing cluster. Within the processing computer cluster, most of the data storage resources are in the form of computers with large raids as well as substantial processing capability. The processing system attempts to locate one copy of specific raw chips on pre-defined computers for each chip. The processing system is aware of this data localization and attempts to target the processing of a particular chip to the machine on which the data for that chip is stored. The output products are then primarily saved back to the same machine. This ‘targetted’ processing was an early design choice to minimize the system wide network load during processing. In practice, as computer disks filled up at different rates, the data has not been localized to a very high degree. The targeted processing has probably reduced the network load somewhat but it has not been as critical of a requirement as originally expected.
The Chip processing stage consists of: reading the raw image into memory, appyling the detrending steps (see Waters et al), stiching the individual OTA cells into a single chip image, detection and characterization of the sources in the image (see Magnier et al), and output of the various data products. These include the detrended chip image, variance image, and mask image, as well as the FITS catalog of detected sources. The PSF model and background model are also saved, along with a processing log. A selection of summary metadata describing the processing results are saved and written to the processing database along with the completion status of the process. Finally, binned chip images are generated (on two scales, binned by 16 and 256 pixels) for use in the visualization system of
the processing monitor tool.
Camera Calibration
After sources have been detected and measured for each of the chip, the next stage is to perform a basic calibration of the full exposure. This stage starts with the collection of FITS tables containing the instrumental measurements of the detected sources, primarily the positions (xccd,yccd) and the instrumental PSF magnitudes. The data for all chips of an ex- posure are loaded by the analysis program. The header information is used to determine the coordinates of the telescope boresite (RA, DEC, Position angle). These three coordinates are used, along with a model of the camera layout, to generate an initial guess for the astrometry of each chip. Reference star coordinates and magnitudes are loaded from a reference catalog for a region corresponding to the boundaries of the exposure, padded by a large fraction of the exposure diameter in case of a modest pointing error. The guess astrometry is used to match the reference catalog to the observed stellar positions in the focal plane coordinate system. Once an acceptable match is found, the astrometric calibration of the individual chips is performed, including a a fit to a single model for the distortion introduced by the camera optics. After the astrometic analysis is completed, the photometric calibration is de- termined using the final match to the reference catalog. At this stage, pre-determined color terms may be included to convert the reference photometry to an appropriate photometric system. For PS1, this is used to generate synthetic w-band photometry for areas where no PS1-based calibrated w-band photometry is available. For more details, see Magnier et al.
In addition to the astrometric and photometric calibrations, the Camera stage also generates the dynamic masks for the images. The dynamic masks include masking for optical ghosts, glints, saturated stars, diffraction spikes, and electronic crosstalk. The mask images generated by the Chip stage are updated with these dynamic masks and a new set of files are saved for the downstream analysis stages.
The Camera stage also merges the binned chip images (see ??) into single jpeg images of the entire focal plane. These jpeg images can then be displayed by the process monitoring system to visualize the data processing.
Warp
Once astrometric and photometric calibrations have been performed, images are geo- metrically transformed into a set of common pixel-grid images with simple projections from the sky. These images, called skycells, can then be used in subsequent stacking and difference image analysis without concern about the astrometric transformation of an exposure. This processing is called ‘warping’; the warp analysis stage is run on all exposures before they are processed further. For details on the warping algorithm, see Waters et al paper.
The output products from the Warp stage consist of the skycell images containing the signal, the variance, and the mask information. These images have been shipped to STScI and are available / will be available from the image extraction tools in DR2.
Stack
The skycell images generated by the Warp process are added together to make deeper, higher signal-to-noise images in the Stack stage. The stacks also fill in coverage gaps between different exposures, resulting in an image of the sky with more uniform coverage than a single exposure. See Waters paper for details on the stack combination algorithm.
In the IPP processing, stacks may be made with various options for the input images. During nightly science processing, the 8 exposures per filter for each Medium Deep field are combined into a set of stacks for that field. These so-called ‘nightly stacks’ are used by the transient survey projects to detect the faint supernovae, among other transient events. For the PV3 3π analysis, all filter images from the 3π survey observation were stacked together to generate a single set of images with ∼ 10 − 20× the exposure of the individual survey exposures. The signal, variance, and mask images resulting from these deep stacks are part of the DR1 release and are available from the image extraction tools.
For the PV3 processing of the Medium Deep fields, stacks have been generated for the nightly groups and for the full depth using all exposures (deep stacks). In addition, a ’best seeing’ set of stack have been produced using image quality cuts to be described. We have also generated out-of-season stacks for the Medium Deep fields, in which all image not from a particular observing season for a field are combined into a stack. These later stacks are useful as deep templates when studying long-term transient events in the Medium Deep fields as they are not (or less) contaminated by the flux of the transients from a given season.
Stack Photometry
The stack images are generated in the Stack stage of the IPP, but the source detec- tion and extraction analysis of those images is deferred until a separate stage, the Stack Photometry stage. This separation is maintained because the stack photometry analysis \is performed on all 5 filter stack images at the same time. By deferring the analysis, the processing system may decouple the generation of the pixels from the source detection. This makes the sequencing of analysis somewhat easier and less subject to blocks due to a failure in the stacking analysis.
The stack photometry algorithms are described in detail in Magnier et al. In short, sources are detected in all 5 filter images down to the 5σ significance. The collection of detected sources is merged into a single master list. If a source is detected in at least two bands, or only in y-band, then a PSF model is fitted to the pixels of the other bands in which the source was not detected. This forced photometry results in lower significance measurements of the flux at the positions of objects which are thought to be real sources, by virtue of triggering a detection in at least two bands. The relaxed limit for y-band is included to allow for searches of y-dropout objects: it is known that faint, high-redshift quasars may be detected in y-band only. The casual user of the PV3 dataset should be wary of sources detected only in y-band as these are likely to have a higher false-positive rate than the other stack sources.
The stack photometry output files consist of a set of FITS tables in a single file, with one file for each filter. Within one of these files, the tables include: the measurements of sources based on the PSF model; aperture like parameters such as the Petrosian flux and radius; the convolved Galaxy model fits; the radial aperture measurements. is this list complete?
The stack photometry output catalogs are re-calibrated for both photometry and as- trometry in a process very similar to the Camera calibration stage. In the case of the stack calibration, however, each skycell is processed independently. The same reference catalog is used for the Camera and Stack calibration stages.
Forced Warp Photometry
Traditionally, projects which use multiple exposures to increase the depth and sensitivity of the observations have generated something equivalent to the stack images produced by the IPP analysis. In theory, the photometry of the stack images produces the ‘best’ photometry catalog, with best sensitivity and the best data quality at all magnitudes (c.f, CFHT Legacy survey, COSMOS, etc). In practice, the stack images have some significant limitations due to the difficulty of modelling the PSF variations. This difficulty is particularly severe for the Pan-STARRS 3π survey stacks due to the combination of the substantial mask fraction of the individual exposures, the large instrinsic image quality variations within a single exposure, and the wide range of image quality conditions under which data were obtained and used to
generate the 3π PV3 stacks.
For any specific stack, the point spread function at a particular location is the result of the combination of the point spread functions for those individual exposures which went into the stack at that point. Because of the high mask fraction, the exposures which contributed to pixels at one location may be somewhat different just a few tens of pixels away. Because of the intrinsic variations in the PSF across an exposure and because of the variations from exposure to exposure, the distribution of point spread functions of the images used at one position may be quite different from those at a nearby location. In the end, the stack images have a effective point spread function which is not just variable, but changing significantly on small scales in a highly textured fashion.
Any measurement which relies on a good knowledge of the PSF at the location of an object either needs to determine the PSF variations present in the stack, or the measurement will be somewhat degraded. The highly textured PSF variations make this a very challenging problem: not would such a PSF model require an unusually fine-grained PSF model, there would likely not be enough PSF stars in an given stack to determine the model at the resolution required. The IPP photometry analysis code uses a PSF model with 2D variations using a grid of at most 6 × 6 samples per skycell, a number reasonably well-matched to the density of stars at most moderate Galactic latitudes. This scale is far too large to track the fine-grained changes apparent in the stack images.
Thus PSF photometry as well as convolved Galaxy models in the stack are degraded by the PSF variations. Aperture-like measurements are in general not as affected by the PSF variations, as long as the aperture in question is large compared to the FWHM of the PSF.
The PV3 3π analysis solves this problem by using the sources detected in the Stack images and performing forced photometry on the individual warp images used to generate the stack. This analysis is performed on all warps for a single filter as a single job, though this is more of a bookkeepping aid as it is not necessary for the analysis of the different warps to know about the results of the other warps.
In the forced warp photometry, the positions of sources are loaded from the stack out- puts. PSF stars are pre-identified and a PSF model generated for each warp based on those stars, using the same stars for all warps to the extent possible (PSF stars which are ex- cessively masked on a particular image are not used to model the PSF). The PSF model is fitted to all of the known source positions in the warp images. Aperture magnitudes, Kron magnitudes, and moments are also measured at this stage for each warp. Note that the flux measurement for a faint, but significant, source from the stack image may be at a low significance (< 5σ) in any individual warp image; the flux may even be negative for specific warps. When combined together, these low-significance measurements will result in a signficant measurement as the signal-to-noise increases by √N.
Forced Galaxy Models
The convolved galaxy models are also re-measured on the warp images by the forced photometry analysis stage. In this analysis, the galaxy models determined by the stack photometry analysis are used to seed the analysis in the individual warps. The purpose of this analysis is the same as the forced PSF photometry: the PSF of the stack is poorly determined due to the masking and PSF variations in the inputs. Without a good PSF model, the PSF-convolved galaxy models are of limited accuracy.
In the forced galaxy model analysis, we assume that the galaxy position and position angle, along with the Sersic index if appropriate, have been sufficiently well determined in the stack analysis. In this case, the goal is to determine the best values for the major and minor axis of the elliptical contour and at the same time the best normalization corresponding to the best elliptical shape (and thus the best galaxy magnitude value).
For each warp image, the Stack value for the major and minor axis are used as the center of a 7×7 grid search of the major and minor axis parameter values. The grid spacing is defined as a function of the signal-to-noise of the galaxy in the stack image so that bright galaxies are measured with a much finer grid spacing that faint galaxies need to quantify this. For each grid point, the major and minor axis values at that point are determined for the model. The model is then generated and convolved with the PSF model for the warp image at that point. The resulting model is then compared to the warp pixel data values and the best fit normalization value is defined. The normalization and the χ2 value for each grid point is recorded.
For a given galaxy, the result is a collection of χ2 values for each of the grid points spanning all warp images. A single χ2 grid can then be made from all warps by combining each grid point across the warps. The combined χ2 for a single grid point is simply the sum of all χ2 values at that point. If, for a single warp image, the galaxy model is excessively masked, then that image will be dropped for all grid points for that galaxy. The reduced χ2 values can be determined by tracking the total number of warp pixels used across all warps to generate the combined χ2 values. From the combined grid of χ2 values, the point in the grid with the minimum χ2 is found. Quadratic interpolation is used to determine the major, minor axis values for the interpolated minimum χ2 value. The errors on these two parameters is then found by determining the contour at which the reduced? χ2 increases by 1.
Thus the Forced Galaxy Model analysis uses the PSF information from each warp to determine a best set of convovled galaxy models for each object in the stack images. discuss the subset of galaxy models and objects.
Difference Images
Two of the primary science drivers for the Pan-STARRS system are the search hazardous asteroids and the search for Type Ia supernovae to measure the history of the expansion of the universe. Both of these projects require the discovery of faint, transient source in the images. For the hazardous asteroids, and solar system studies in general, the sources are transient because they are moving between observations; supernovae are stationary but transient in brightness. In both cases, the discovery of these sources can be enhanced by subtracting a static reference image from the image taken at a certain epoch. The quality of such a difference image can be enhanced by convolving one or both of the images so that the PSFs in the two images are matched. discuss Alard-Lupton.
In the Difference Image stage, the IPP generates diffferece images for specified pairs of images. It is possible for the difference image to be generated from a pair of warp images, from a warp and a stack of some variety, or from a pair of stacks. During the PS1 survey, pairs of exposures, call TTI pairs (see Survey Strategy), were obtained for each pointing within a ∼ 1 hour period in the same filter, and to the extent possible with the same orientation and boresite position. The standard PS1 nightly processing generated difference images from the resulting warp pairs (‘warp-warp diffs’).
The nightly stacks generated for the Medium Deep fields were combined with a template reference stack image to generate ‘stack-stack diffs’ for these fields each night.
For the PV3 processing, the entire collection of warps for the 3π survey were combined with the 3π stacks to generate ‘warp-stack diffs’.
Information for this page should come from Magnier et al 2016.
Parent page for the description of PSPS processing.
Planned contents:
| Excerpt |
|---|
|
PS1 Forced photometry of sources on the individual warp images.
The PS1 Relative Photometric Calibration is determined by the photometric calibration algorithm of Schlafly et al. (2012), which refines the photometric calibration algorithm of Padmanabhan et al. (2008), used in the Sloan Digital Sky Survey. The throughput of the system is modeled with as a constant system throughput and atmospheric k-term each night. The model is determined by finding the parameters of the model that minimize the variance in flux of repeated observations of the same sources. The photometric calibration also simultaneously fits for a low resolution flat field correction vector and a trend in system throughput with PSF.
The PS1 Absolute photometric calibration combines the use of a laser diode system to accurately and precisely determine the filter bandpass edges and throughput curves (roughly to 7 A in mean effective wavelength), with the PS1 observations of HST Calspec standards.
The PS1 Astrometry is anchored with the Gaia astrometry.
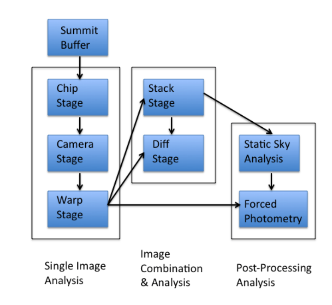
Schematic of the images and analysis processing stage of the PS1 IPP pipeline, described in Magnier et al.